특정 요소를 기준으로 데이터를 정렬할 수 있습니다.
퀵 정렬 알고리즘과 같은 방식으로 정렬할 수 있지만 정렬에는 대가가 따릅니다.
또한 정렬된 데이터 구조에서 데이터가 변경될 때마다 정렬된 상태를 유지하기 위해 정렬 비용을 지속적으로 지불해야 합니다.
빠른 삽입 및 삭제가 가능한 정렬된 데이터 구조만약 있다면?
놀랍게도 이러한 데이터 구조가 존재합니다.
오늘은 그걸 포스팅합니다 “나무”보지마.
1. 나무란?
트리는 노드 기반 데이터 구조이지만 구성 요소인 각 노드는 여러 노드에 대한 링크를 포함할 수 있습니다.
생김새가 나무를 닮았다 하여 나무라는 이름이 붙었습니다.
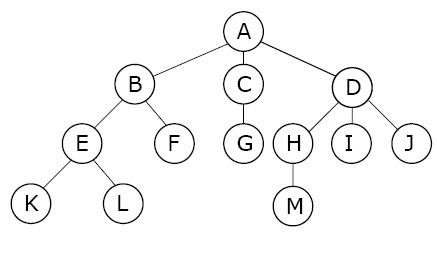
2. 나무에 대한 기본 용어
트리 데이터 구조에는 트리에서만 사용되는 고유한 용어가 있습니다.
- 최상위 노드 뿌리 (뿌리)이름을 짓다
- 특정 노드 바로 위에 있는 상위 노드 부모 (부모의)바로 아래 하위 노드 어린이 (어린이)그것은 ~라고 불린다.
- 특정 노드로 연결되는 모든 노드 선조 (선조)주어진 노드에서 시작되는 모든 노드 자손 (자손)그것은 ~라고 불린다.
- 나무에서 심지어 (심지어)존재하며 각 레벨은 트리에서 동일한 행입니다.
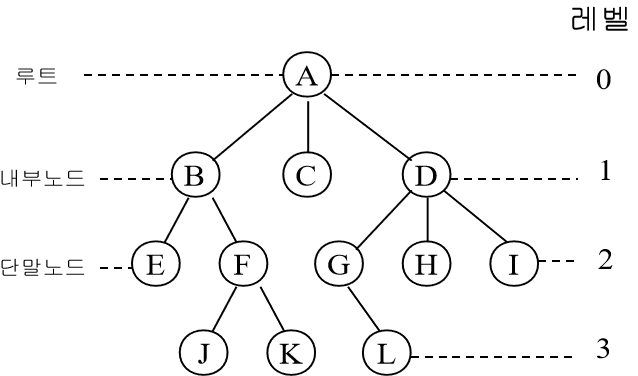
- 나무의 재산균형의 정도를 의미하며 하위 트리의 노드 수가 모든 노드에서 동일하면 트리는 밸런스 트리보지마.
3. 이진 검색 트리
트리 기반 데이터 구조는 다양하지만 이 게시물에서는 이진 검색 트리이야기하자
이진 검색 트리에는 다음과 같은 규칙이 있습니다.
- 각 노드의 자식은 왼쪽 하나, 오른쪽 하나 존재할 수 있습니다.
- 매듭 왼쪽 자손은 이 노드보다 작은 값입니다.만 포함할 수 있습니다 오른쪽 자손이 이 노드보다 큽니다.만 포함할 수 있습니다
코드에서 다음과 같이 구현할 수 있습니다.
class BinaryTreeNode {
data;
leftChild;
rightChild;
constructor(data, leftChild = null, rightChild = null) {
this.data = data;
this.leftChild = leftChild;
this.rightChild = rightChild;
}
}
4. 이진 검색 트리 검색
이번에는 이진 검색 트리 데이터 구조를 계산하는 동안 구하다알아 보자
검색은 다음과 같이 진행됩니다.
- 현재 노드로 확인할 노드를 지정합니다. ( 루트 노드에서 시작 )
- 현재 노드의 값을 확인하십시오.
- 찾고 있는 값의 현재 노드를 반환합니다.
- 찾으려는 값이 현재 노드보다 작으면 왼쪽 하위 트리를 순서대로 검색합니다.
- 찾으려는 값이 현재 노드보다 크면 오른쪽 하위 트리를 순서대로 검색합니다.
- 찾고 있는 값을 찾거나 트리 맨 아래에 도달할 때까지(자식이 더 이상 없는 경우) 1~5단계를 반복합니다.
코드로 구현해 보겠습니다.
search(searchValue, node) {
// 기저 조건 : 바닥에 도달하거나 찾고자 하는 값을 찾은 경우
if (node === null || node.data === searchValue) {
return node;
// 현재 노드 값이 찾고자 하는 값보다 작은 경우 왼쪽 자식 방향으로 검색
} else if (node.data < searchValue) {
return search(searchValue, node.leftChild)
// 현재 노드 값이 찾고자 하는 값보다 큰 경우 오른쪽 자식 방향으로 검색
} else {
return search(searchValue, node.rightChild)
}
}검색 영역이 절반으로 줄어들기 때문에 시간 복잡도는 $O(logN)$가 나옵니다.
5. 이진 검색 트리 삽입
이진 검색 트리 끼워 넣다다른 데이터 구조에 비해 매우 뛰어납니다.
역시나 검색처럼 비교해서 내려갑니다.
더 이상 노드가 내려갈 수 없을 때 노드의 값보다 작으면 왼쪽 위치에, 크면 오른쪽 위치에 노드를 삽입합니다.
검색 – $logN $step + insert – $1 $step이 필요하기 때문에 시간 복잡도는 $O(logN)$가 됩니다.
코드로 구현해 보겠습니다.
function insert(data, node) {
// 삽입하고자 하는 데이터가 현재 노드 데이터 보다 작은 경우
if (data < node.data) {
// 왼쪽 자식 위치가 비어있다면 해당 위치로 삽입
if (node.leftChild === null) {
node.leftChild = new Node(data, null, null)
} else {
// 왼쪽 자식 위치에 노드가 존재 한다면 왼쪽 자식 따라 이동
insert(data, node.leftChild)
}
// 삽입하고자 하는 데이터가 현재 노드 데이터 보다 큰 경우
} else if (data > node.data) {
// 오른쪽 자식 위치가 비어있다면 해당 위치로 삽입
if (node.rightChild === null) {
node.rightChild = new Node(data, null, null)
} else {
// 오른쪽 자식 위치에 노드가 존재 한다면 오른쪽 자식 따라 이동
insert(data, node.rightChild)
}
}
}
동일한 값을 가진 요소가 트리에 삽입되더라도 삽입된 순서에 따라 다른 유형의 트리가 생성됩니다.
정렬된 입력 순서는 균형이 맞지 않는 트리와 성능 저하로 이어집니다.
6. 이진 검색 트리 삭제
삭제는 이진 검색 트리에서 가장 어려운 작업이므로 신중하게 수행해야 합니다.
규칙은 다음과 같습니다.
- 삭제할 노드에 자식이 없습니다.얼굴 매듭을 즉시 삭제하십시오.
- 삭제할 노드의 자식노드를 삭제하고 삭제된 노드가 있던 곳에 자식을 둡니다.
- 자식이 두 개인 노드를 삭제할 때삭제된 노드입니다 후속 노드로 교체하십시오. 후속 노드란 무엇입니까? 가장 작은 값이 삭제된 노드보다 큽니다.가 있는 하위 노드입니다.
- 후속 노드 찾기 삭제된 값의 오른쪽 자식을 방문하고 왼쪽 자식이 없을 때까지 해당 자식의 왼쪽 자식을 계속 방문합니다. 우리는 내려간다 하한가이것은 후속 노드입니다.
- 자손 노드의 오른쪽 자식이 있으면 삭제된 노드가 있던 자리에 자손 노드를 배치합니다. 자식 노드의 오른쪽 자식은 자식 노드의 원래 부모 노드의 왼쪽 자식입니다.안에.
몇 가지 규칙이 있습니다.
코드로 구현해 보겠습니다.
function deleteNode(valueToDelete, node) {
// 트리 바닥에 도달한 경우 기저 조건
if (node === null) {
return null
}
// 삭제하려는 값이 현재 노드보다 크거나 작으면
// 현재 노드의 왼쪽 혹은 오른쪽 하위 트리에 대한 재귀 호출의 반환 값을
// 각각 왼쪽 혹은 오른쪽 자식에 할당
// ( 실제 자식 노드들이 자기 자신을 반환 하는 경우가 다수 )
else if (valueToDelete < node.data) {
node.leftChild = deleteNode(valueToDelete, node.leftChild)
return node
} else if (valueToDelete > node.data) {
node.rightChild = deleteNode(valueToDelete, node.rightChild)
}
// 현재 노드가 삭제 하려는 노드인 경우
else if (valueToDelete === node.data) {
// 현재 노드에 한쪽 자식이 없는 경우 해당 노드를 상위 노드의 자식으로 반환
// 하여 현재 노드 삭제
if (node.leftChild === null) {
return node.rightChild
} else if (node.rightChild === null) {
return node.leftChild
}
// 현재 노드에 자식이 둘 존재하는 경우 후속자 노드의 값으로 바꿈
// lift 함수 호출로 현재 노드 삭제
else {
node.rightChild = lift(node.rightChild, node)
return node
}
}
}
// 1. 후속자 노드를 찾는다
// 2. nodeToDelete 값을 후속자 노드로 덮어쓴다. 후속자 노드 객체를 옮기는 것이 아닌 그 값을 삭제중인 노드에 복사
// 3. 실제 후속자 노드 객체를 삭제하기 위해 원래 후속자 노드의 오른쪽 자식을 후속자 노드의 부모의 왼쪽 자식으로 넣는다.
// 4. 재귀가 모두 끝나면 처음에 전달 받은 rightchild를 반환하거나 원래 rightChild에 왼쪽 자식이 없어 원래
// rigthChild가 후속자 노드가 되었으면 null을 반환한다.
function lift(node, nodeToDelete) {
// 현재 노드에 왼쪽 자식이 있으면
// 왼쪽 하위 트리로 계속해서 내려가도록 재귀호출하여
// 후속자 노드를 찾는다
if (node.leftChild !== null) {
node.leftChild = lift(node.leftChild, nodeToDelete)
return node
}
// 현재 노드의 왼쪽 자식이 없는 경우
// 이 함수의 현재 노드가 후속자 노드라는 뜻이므로
// 현재 노드의 값을 삭제하려는 노드의 새로운 값으로 할당한다
else {
nodeToDelete.data = node.data
// 후속자 노드의 오른쪽 자식이 부모의 왼쪽 자식으로 쓰일수 있게 반환한다.
return node.rightChild
}
작업 삭제 시간복잡도가 너무 $ O(logN) $.
7. 이진 검색 트리 순회
이진 검색 트리를 정렬된 순서대로 인쇄하려면 어떻게 해야 합니까?
먼저 트리의 각 노드를 방문해야 합니다.
데이터 구조의 모든 노드를 방문하는 프로세스 회로 (횡단)이름을 짓다
둘째, 목록을 순서대로 인쇄할 수 있어야 합니다.
이 게시물에서 중위 서클 (순서대로 실행)로 알려진 방법 오름차순나는 그것을 할 것이다
중간 패스는 다음 순서로 발생합니다.
- 노드의 왼쪽 자식에서 함수를 재귀적으로 호출합니다.
- 현재 노드를 방문하십시오.
- 노드의 오른쪽 자식에서 재귀적으로 함수를 호출합니다.
코드에서 다음과 같이 구현할 수 있습니다.
traverseAndPrint(node){
if(node === null) return
this.traverseAndPrint(node.leftChild)
console.log(node.data)
this.traverseAndPrint(node.rightChild)
}
마지막으로
트리는 계산 프로세스가 더 복잡하고 더 많은 규칙이 있기 때문에 다른 데이터 구조보다 더 효율적입니다.
이진 검색 트리 외에도 특별한 상황에서 잘 작동하는 다른 유형의 트리가 있습니다.
다음 게시물에서 더 많이 소개하겠습니다.
감사해요